
Information about a domain
There are many vulnerabilities and techniques about a domain and I will show you below:
1.- Enter https://spyse.com/user/registration
2.- Create an account and log in
SPF not established
Sample report: https://hackerone.com/reports/120
With spyse.com this type of attack is easily detectable only by performing the steps below:
1.- Enter spyse.com with your valid credentials
2.- Enter the domain you want to verify, example: twitter.com

3.- Now go to the navigation where it says TXT records if it shows nothing it is vulnerable

Note: in this case twitter includes your spf record: v= spf1 ip4: 199.16.156.0/22 ...
In simple steps you can recognize this vulnerability with which an attacker can perform phishing and that emails reach their inbox.
List subdomains in search of Subdomain Takeover
report example: https://hackerone.com/reports/661751
With spyse.com this type of attack is easily detectable, we only carry out the following steps:
1.- Enter spyse.com with your valid credentials
2.- Enter the domain you want to verify, example: twitter.com

3.- in the navigation bar click subdomain list

4.- check the cname of each site
5.- enter each site and if it responds incorrectly and has a cname associated it may be a possible takeover subdomain
6.- You can consult a list of services that allow this attack: https://github.com/EdOverflow/can-i-take-over-xyz
So with spyse we can see the subdomains and find subdomain takeover. In this case of twitter there is none.
Missing security headers
Missing security headings can lead to higher risks sometimes they are reported, some sample reports can be found here:
https://hackerone.com/reports/64645
https://hackerone.com/reports/163676
https://hackerone.com/reports/17239
https://hackerone.com/reports/231805
To review these settings it is possible to use spyse.com by performing the following steps:
1.- Enter spyse.com with your valid credentials
2.- Enter the domain you want to verify, example: twitter.com

3.- In the navigation bar click on common info
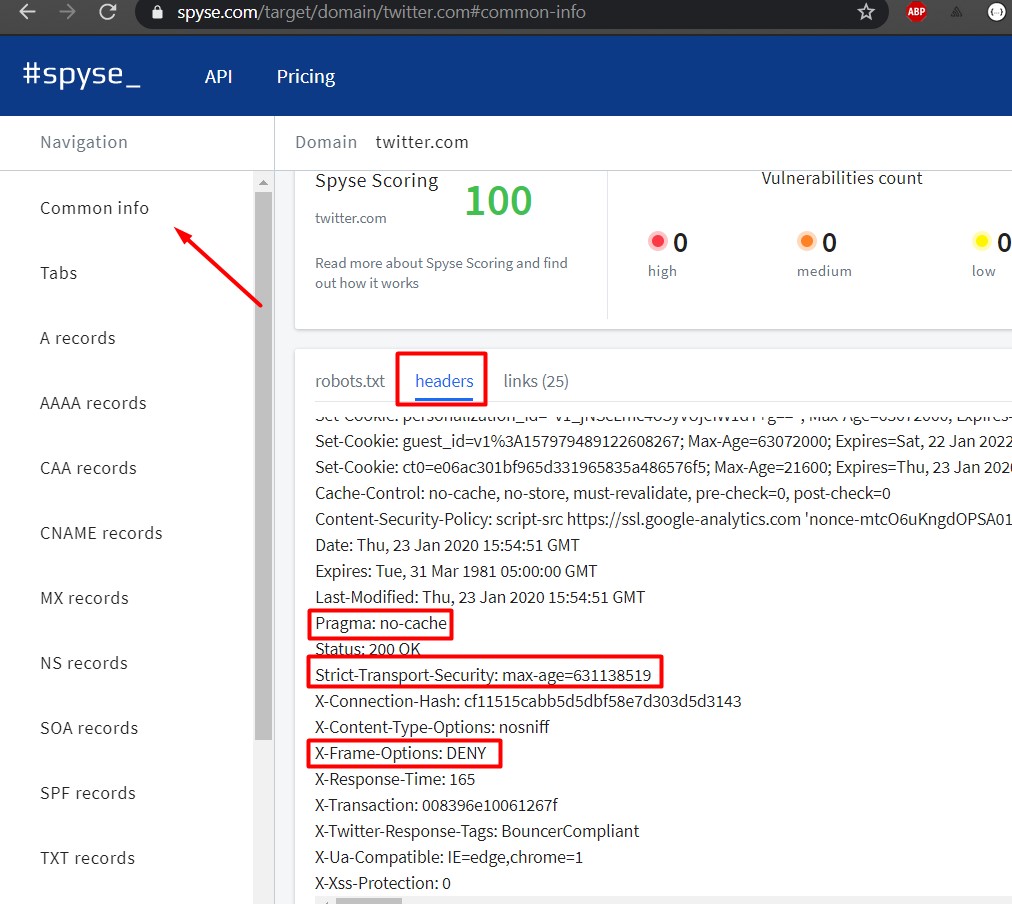
4.- click on headers
5.- Check that there is no need for a security heading such as the one in the example reports:
- X-Frame-Options
- Content-Security-Policy
- Strict-Transport-Security
- Cache-Control
- Pragma
if one is missing it is vulnerable. Although this is a practical improvement so that they cannot reach attacks on the browser side, it is useful to implement security on them.
Detect domains or subdomains with the same IP (within the same server)
Many times the main applications are not vulnerable to some type of common attack such as: XSS, SQLi, IDOR, RCE, etc.
This does not mean that privileges cannot be elevated on the server using a subdomain or domain within the same server, gaining access to the main website. It is also possible to find the real IP of the server if it uses any WAF to avoid it.
Sample report: https://hackerone.com/reports/315838
For this it is possible to detect with spyse which domains or subdomains are within the same server. Take the steps below to detect them:
1.- Enter spyse.com with your valid credentials
2.- Enter the domain you want to verify, example: twitter.com

3.- In the navigation bar click on Domains in same IP

4.- Find if it is possible to find vulnerabilities in this Host or if it finds the real IP of the host in the DNS that points to A
Vulnerability counter
Depending on the technologies used, it is possible to detect if the host has vulnerabilities and depending on it it shows you the criticality.
To test this on spyse.com just follow the steps below:
1.- Enter spyse.com with your valid credentials
2.- Enter the domain you want to verify, example: testphp.vulnweb.com

3.- Check the vulnerability counter.

Lastly, that is not all you can do with spyse, you can also find information such as: the robots.txt file which contains important information such as links or hidden features, there is also a links section to see indexed links, and you can see ASN or Organizations listing different servers from the same organization which widens the scope for an ethical hacker.
Also if you are one of those who like captures for each subdomain with spyse it is possible to automate this and more using the API.
And if it were not all it includes an API with which you could automate this whole process from your server by running a cronjob in search of information or automated recognition with spyse.
An example of using the api can be the following:
curl -X GET "https://api.spyse.com/v2/data/domain?limit=100&name=twitter.com" -H "accept: application / json" -H "Authorization: Bearer xxx-xxx-xxx- xxx-xxxx "| jq

parsing this information can be very useful for automated collection.
Without further ado I recommend registering and buying a subscription on spyse.com (https://spyse.com/user/subscription) with which security consultants, security companies or bug hunters could take full advantage.



















